
یکی از مباحث مهم و مطرح در دنیای امروز ذخیره سازی و پردازش کلان داده ها (Big data) می باشد. کلان داده، به داده هایی گفته میشود که مدیریت و پردازش آنها خارج از توانایی راه حلها و سیستم های موجود است.
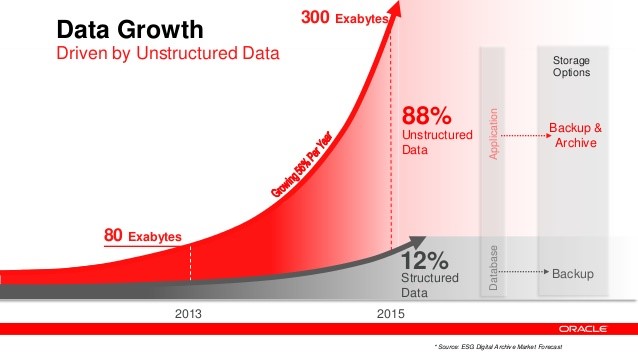
حدود ۹۰ درصد کل داده هایی که در جهان موجود است در چند سال گذشته تولید شده است (عکس، ویدئو، حرکت ماوس، لایک ها و...). همچنین تنوع داده و افزایش داده های غیرساختارمند باعث شد شرکت های بزرگ همچون گوگل، یاهو و... باحجم و تنوع بسیار زیاد از داده هایی که کاربرانشان تولید میکنند روبه رو شوند. ذخیره این حجم بالایی از داده با تنوع زیاد بر روی کامپیوترها و ماشین های ارزان قیمت و ابزارهایی مانند اوراکل و ... امکان پذیر نیست.
یکی از کارهای اولیه که در این زمینه پیشنهاد میشود ، فشرده سازی داده هاست. این امر در داده های بزرگ چندان کارساز نیست ، زیرا یکی دیگر از خصوصیات داده های بزرگ ، تنوع آنها است. این داده ها از انواع مختلفی تشکیل شده اند که این غیرساخت یافتگی ، فشرده سازی آن ها را دشوار کرده و در بعضی شرایط به گونه ای است که همان زمانی که برای پردازش آنها به واسطه روش های سنتی صرف میشود ، برای فشرده سازی هدر میرود. به همین دلیل فشرده سازی کاربردی در پردازش داده های بزرگ ندارد.
از آنجا که پردازش و ذخیره سازی داده ها کاری بسیار مشکل است؛ با روبهرو شدن با این چالش جدید دانشمندان به دنبال راه حل و ابزارهای جدید برای مدیریت و پردازش کلان داده ابزارهای مختلفی را تولید کردند. یکی از این ابزارها و محبوب ترین آنها هدوپ نام دارد. هدوپ (Hadoop) را حتی بر روی سیستم های ارزان قیمت و معمولی میتوان نصب و اجرا کرد و دیگر نیازی به کامپیوترهای گران قیمت و غول آسا نیست و میتوان با شبکه کردن چند کامپیوتر معمولی و تقسیم داده ها بر روی این کامپیوترها، کلان داده ها را مدیریت کرد.
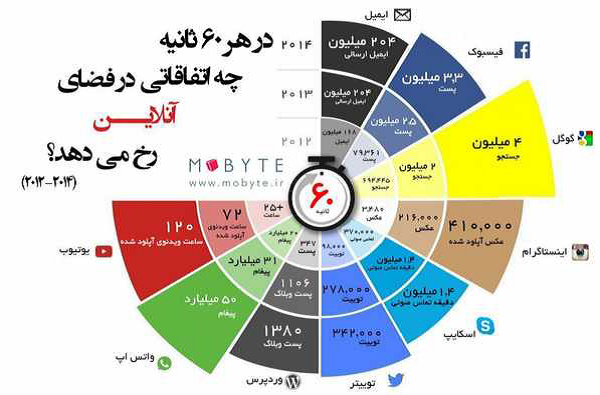
در تصویر زیر نمونه هایی از کلان داده که در یک دقیقه تولید میشوند نشان داده شده است:
کلان داده چیست؟
عبارت کلان داده مدتها است که برای اشاره به حجم عظیمی از داده ها که توسط سازمان های بزرگی مانند گوگل یا ناسا ذخیره و تحلیل میشوند مورد استفاده قرار میگیرند و معمولا به دادههایی گفته میشود که اندازه آنها فراتر از حدی است که با نرمافزارهای معمول بتوان آنها را در یک زمان معقول پردازش کرد.
طبق تعریف مؤسسه تحقیقاتی گارتنر: کلان داده، داده هایی هستند بسیار انبوه، پرسرعت و گوناگون که نیاز به روش های پردازشی تازه ای دارند و دائما از لحاظ حجم، نرخ تولید داده و تنوع در حال تغییر هستند.
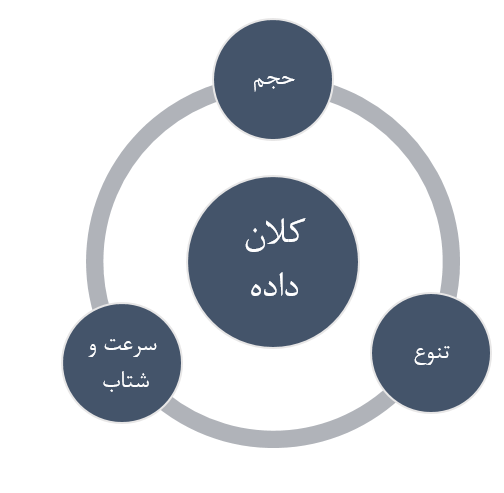
معیارهای تشخیص کلان داده
حجم (Volume) بالا به تنهایی معیار مناسبی برای تشخیص کلان داده نیست؛ علاوه بر حجم سرعت (Velocity) و تنوع (Variety) نیز از معیارهای اصلی و مهم برای تشخیص کلان داده میباشند. معیارهای فرعی دیگری نیز وجود دارند که تا ده مورد را میتوان نام برد.
حجم داده
حجم داده ها به صورت نمایی در حال رشد است. منابع مختلفی نظیر شبکه های اجتماعی، سرورهای وب، تصاویر ماهواره ای، تراکنش های بانکی، محتوای صفحات وب، اسناد دولتی و ... وجود دارد که حجم بسیار زیادی تولید میکنند.
نرخ تولید داده یا سرعت
داده ها از طریق برنامه های کاربردی و سنسورها با سرعت بسیار زیاد و به صورت بلادرنگ تولید میشوند. بسیاری از کاربردها نیاز دارند به محض ورود داده به درخواست کاربر پاسخ دهند.
برای مثال شرکتی که نرخ تولید داده هایش درسال یا هر دو سال یکبار حدود 1درصد باشداستفاده از هدوپ و کلان داده توصیه نمیشود. اما توییتر یک بیلیون توییت در هر 72 ساعت از 140 میلیون فعالیت کاربران توییتر دارد که نرخ تولید قابل توجهی است.
تنوع
انواع منابع داده و تنوع در نوع داده بسیار زیاد است که در نتیجه ساختارهای داده ای بسیار زیادی وجود دارد. مثلا در وب افراد از نرم افزارها و مرورگرهای مختلفی برای ارسال اطلاعات استفاده میکنند. بسیاری از اطلاعات مستقیما از انسان دریافت میشود و بنابراین وجود خطا اجتنابناپذیر است. این تنوع سبب میشود جامعیت داده تحت تاثیر قرار بگیرد؛ زیرا هرچه تنوع بیشتری وجود داشته باشد، احتمال بروز خطای بیشتری نیز وجود خواهد داشت.
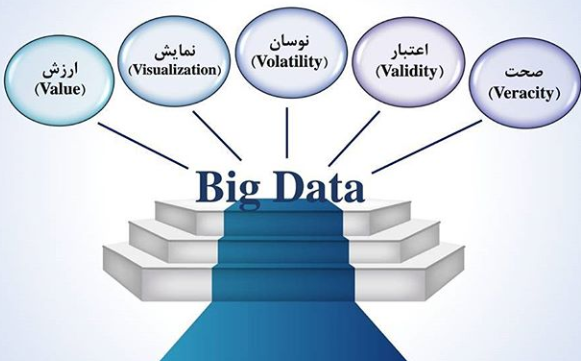
معیارهای اصلی تشخیص کلان داده:
![آمار کلان داده ها]() صحت (Veracity)
صحت (Veracity)
 صحت (Veracity)
صحت (Veracity)با توجه به اینکه داده ها از منابع مختلف دریافت میشوند، ممکن است نتوان به همه آنها اعتماد کرد. مثلا در یک شبکه اجتماعی، ممکن است نظرهای زیادی در خصوص یک موضوع خاص ارائه شود. اما اینکه آیا همه آنها صحیح و قابل اطمینان هستند، موضوعی است که نمیتوان به سادگی از کنار آن در حجم بسیاری زیادی از اطلاعات گذشت. البته بعضی تحقیقات این چالش را به معنای حفظ همه ی مشخصه های داده اصلی بیان کرده اند که باید حفظ شود تا بتوان کیفیت و صحت داده را تضمین کرد.
اعتبار (Validity)
با فرض اینکه داده صحیح باشد، ممکن است برای برخی کاربردها مناسب نباشد یا به عبارت دیگر از اعتبار کافی برای استفاده در برخی از کاربردها برخوردار نباشد.
نمایش (Visualization)
یکی از کارهای مشکل در حوزه کلان داده، نمایش اطلاعات است .اینکه بخواهیم کاری کنیم که حجم عظیم اطلاعات با ارتباطات پیچیده، به خوبی قابل فهم و قابل مطالعه باشد از طریق روش های تحلیلی و بصری سازی مناسب اطلاعات امکان پذیری است.
ارزش (Value)
این موضوع دلالت بر این دارد که از نظر اطلاعاتی برای تصمیم گیری چقدر داده حائز ارزش است . به عبارت دیگر آیا هزینه ای که برای نگهداری داده و پردازش آنها میشود، ارزش آن را از نظر تصمیمگیری دارد یا نه.
نوسان (Volatility)
سرعت تغییر ارزش داده های مختلف در طول زمان میتواند متفاوت باشد. در یک سیستم معمولی تجارت الکترونیک، سرعت نوسان داده ها زیاد نیست و ممکن است داده های موجود مثلا برای یک سال ارزش خود
را حفظ کنند. اما در کاربردهایی نظیر تحلیل ارز و بورس، داده ها با نوسان زیادی مواجه هستند و داده ها به سرعت ارزش خود را از دست میدهند و مقادیر جدیدی به خود میگیرند. اگرچه نگه داری اطلاعات در زمان طولانی به منظور تحلیل تغییرات و نوسان داده ها حائز اهمیت است ؛ افزایش دوره نگهداری اطلاعات، مسلما هزینه های پیاده سازی زیادی را در بر خواهد داشت که باید در نظر گرفته شود.










فروهمند
مقاله ی خیلی کاملی بود. مبحث بیگ دیتا و کلان داده خیلی جدیده و تو سایتای فارسی چیز زیادی نمیشه پیدا کرد. امیدوارم مقالاتتون ادامه دار باشه